How to intersect two array of different column in pyspark dataframe ?
大家應該都有相關的經驗在使用 spark 處理 array 類型資料時常常會遇到很多卡卡的問題,尤其在比較舊的 spark 版本基本上都只能自己寫 udf 解決一些問題。本篇將會分享如何針對兩個 column 的 array 進行 intersect,其中包含找到重複值 array_intersect 以及 找到不重複值的 array_except,此用法為 spark 2.4 才新增的用法,輕鬆地解決之前還要寫 udf 的麻煩。
在本範例你會學到:
array_intersect使用方式array_except使用方式
在本範例你需要先準備好:
- 本範例部份 function 只適用於
spark 版本 >= 2.4 - 歡樂愉快的學習精神
本文將建立一個簡單的範例,資料集如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.types import *
spark = SparkSession.builder.appName('intersect').getOrCreate()
# Create dataset
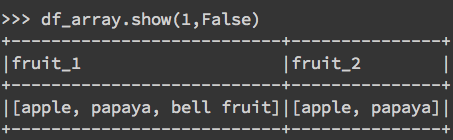
df_array = spark.createDataFrame([(["apple","papaya","bell fruit"], ["apple","papaya"])], ["fruit_1", "fruit_2"])
# show
df_array.show(1,False)
1. array_intersect
array_intersect 的用法與概念相當的簡單,就如同 python 中的 set(a) & set(b),將會找出兩個資料及相同的值,下列範例會找到 "apple","papaya":
df_array.withColumn('array_intersect',F.array_intersect(F.col('fruit_1'),F.col('fruit_2'))).show(1,False)
2. array_except
而 array_except則相反,將會留下兩個資料集沒有同時有相同的資料,如下所示,bell fruit只出現在了第二個 column,所以會被留下:
df_array.withColumn('array_except',F.array_except(F.col('fruit_1'),F.col('fruit_2'))).show(1,False)
大功告成!
參考資料
在 pyspark.sql.functions 其實有許多好用的小 function 可以直接使用,也不用再自己辛苦的寫 udf(User Defined function),在之後的介紹會再慢慢帶給大家。下方為今天介紹的兩種好用的小function。
https://spark.apache.org/docs/latest/api/python/pyspark.sql.html#pyspark.sql.functions.array_except

