How to use collect_list & collect_set in pyspark dataframe?
在使用 spark 操作 dataframe 時常常會做合併 (groupby與 aggregation) 與展開 (explode) 的動作,尤其在合併時就會考慮到要保留下原始資料還是要去重複的問題,本文將會介紹 collect_list 與collect_set的用法以及稍微提及可能會遇到的例外狀況的解決方式 (array_distinct 與 flatten)。
在本範例你會學到:
collect_list使用方式collect_set使用方式array_distinct(New in version spark 2.4) 使用方式flatten(New in version spark 2.4) 使用方式
在本範例你需要先準備好:
- 本範例部份 function 可能只適用於
spark 版本 >= 2.4 - 歡樂愉快的學習精神
本文將假設一個簡單的範例,學校相關單位做了一份問券調查,調查關於小學生一天之中早、午、晚餐分別喜歡吃哪些水果,再將這些結果整理與分析再利用。資料集如下:
#!/usr/bin/env python |
1. collect_list
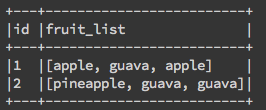
若單純的想要知道每個學生喜歡水果的概覽,可以直接使用 collect_list:
df.groupBy('id').agg(F.collect_list(F.col('fruit')).alias('fruit_list')).show(2,False) |
2. collect_set
可以發現,上方的例子學生如果某兩餐吃的一樣就會重複出現相同的水果,若想要知道水果的種類(distinct)就可以使用collect_set:
df.groupBy('id').agg(F.collect_set(F.col('fruit')).alias('fruit_list')).show(2,False) |
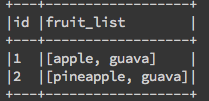
collect_set的意義就是平常 python中常使用的 set()是一樣的概念,去除重複的資料。
3. 當 Array 遇上 collect_set 與 collect_list
這裡就要提到實戰中常遇到的問題,如果我本身的資料就是一個 array 呢?在使用 collect_set 與 collect_list 會發生什麼事呢?我們往下看下去。接續上述的使用情境創造資料集,此時學生的每一餐都可以寫一個以上的水果的話:
# 學生每一餐都可以填超過一個種類以上的水果 |
我們就簡單的將前面的範例直接套下來,用一樣的方式使用collect_list:
# collect_list |

與collect_set:
# collect_set |
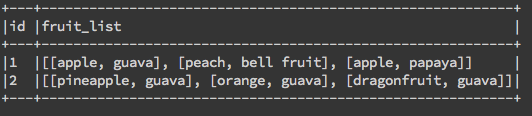
大家應該不難發現,其實上面兩個結果是完全相同的(除了array 內順序不同),這是怎麼回事呢?
4. 使用 array_distinct 與 flatten 解決
因為他已經變成了 array 中的 array,在裡面的 array 都已經被視為不同的個體了,他不會自動的合併在一起(ex: ["apple","papaya"] 與 ["apple","guava"] 是兩個完全不同的內容):
[["apple","papaya"],["apple","guava"],["peach","bell fruit"]] |
解決方式可以搭配之前所說的 array_distinct 與 flatten 來解決。
flatten主要作用是解開 array of array,ex:[["apple","papaya"],["apple","guava"],["peach","bell fruit"]]會被解開成["apple","papaya","apple","guava","peach","bell fruit"]。array_distinct作用與set()相同,就是去重複拉!
df_array.groupBy('id').agg(F.array_distinct(F.flatten(F.collect_set('fruit'))).alias('fruit_list')).show(2,False) |
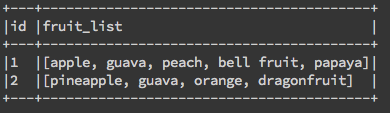
大功告成!
參考資料
在 pyspark.sql.functions 其實有許多好用的小 function 可以直接使用,也不用再自己辛苦的寫 udf(User Defined function),在之後的介紹會再慢慢帶給大家。下方為今天介紹的四種好用的小function。
https://spark.apache.org/docs/latest/api/python/pyspark.sql.html#pyspark.sql.functions.collect_list
https://spark.apache.org/docs/latest/api/python/pyspark.sql.html#pyspark.sql.functions.collect_set
https://spark.apache.org/docs/latest/api/python/pyspark.sql.html#pyspark.sql.functions.flatten

